
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- hash table
- input
- array
- 자바입력
- Kadane's Algorithm
- R
- SpringBoot 2
- 자바 스레드 실행 순서 제어
- 사칙연산
- JAVA11
- 자바 thread 실행 순서 제어
- Easy
- 카데인 알고리즘
- heroku
- 수학
- scanner
- Today
- Total
목록Data Structure, Algorithm (15)
DeFacto-Standard IT
 트리 - 너비 우선 탐색 알고리즘 (BFS)
트리 - 너비 우선 탐색 알고리즘 (BFS)
너비 우선 탐색 알고리즘 (BFS, Breadth First Search) 트리를 조회할 때, 너비를 기반하여 우선적으로 조회한다. 하나의 노드에는 여러 개의 노드가 연결되어 있는데, 특정 노드와 근접한 노드부터 검사한다. 트리에는 깊이라는 개념이 있다. 0번 노드는 깊이가 1이며, 1, 2번 노드는 깊이가 2이다. 그 밑으로 3, 4, 5, 6번 노드는 깊이가 3이고, 그 이후는 1씩 추가된다. 너비 우선 탐색(BFS)는 깊이 우선 탐색(DFS)과 다르게, 루트 노드에 인접한 노드를 먼저 모두 검사한 후, 그 다음 서브 노드로 옮겨서 그 서브 노드에 인접한 모든 노드를 검사하는 방식으로 동작한다. BFS의 구현은 DFS에서 사용했던 Recursive Call 만을 사용해서는 구현하기 힘들다. Recur..
 트리 - 깊이 우선 탐색 알고리즘 (DFS)
트리 - 깊이 우선 탐색 알고리즘 (DFS)
깊이 우선 탐색 알고리즘(DFS, Depth First Search) 트리를 조회할 때, 깊이를 기반하여 우선적으로 조회한다. 하나의 노드에는 여러 개의 노드가 연결되어 있는데, 특정 노드의 한쪽 방향의 끝까지 먼저 검색한 후 다른 방향의 노드를 검사한다. 구현은 Recursive Call 혹은 Stack을 사용한다. 위 그림에서 0번 노드시작으로, 왼쪽 노드부터 내려가면서 1. 자신 검사 2. 왼쪽 노드 검사 3. 오른쪽 노드 검사 를 반복하게 된다. 이 때, 왼쪽 또는 오른쪽의 서브노드 검사 중 서브노드의 왼쪽, 오른쪽 서브노드가 또 있으면 위 과정을 계속해서 반복하게 된다. 트리는 배열로도 표현할 수 있지만, LinkedList로 표현하는 것이 일반적이다. 각 노드는 left, right라는 서브 ..
 이진탐색 (BinarySearch)
이진탐색 (BinarySearch)
분할 정복 알고리즘의 일부 탐색법이다. 검색해야 할 대상(arr)을 절반씩 잘라서, 찾으려는 숫자(target)의 범위를 포함하는 서브 대상에서 다시 똑같은 방법으로 찾는다. 단, 절반으로 잘라서 찾는 분할정복법의 특정 상 속도는 굉장히 빠르지만, 배열은 정렬이 되어 있어야 한다는 제약이 따른다. [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] 이라는 배열이 있고, 여기서 8을 찾는다고 가정해보자. left는 찾으려는 현재 배열의 가장 작은 값(가장 왼쪽 값) right는 찾으려는 현재 배열의 가장 큰 값(가장 오른쪽 값) mid는 찾으려는 현재 배열의 중간값 (가장 가운데 값) 을 뜻한다. - 1차 계산 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] 현재 배열에서 le..
- 개념 계산한 결과가 이후에 또 다시 필요할 경우, 재계산하지 않고 저장해놨다가 다음 계산에 재사용하는 알고리즘. - 대표적인 문제 LeetCode - 53. Maximum Subarray
복호화가 가능한지의 여부이다. Hashing – 결과 값에서 원본 값을 추출할 수 없는 단방향 알고리즘. 해싱 알고리즘에 의해 한 plain text에 대해 고정된 길이의 값이 생성된다. 인증에 사용. 대표 알고리즘 MD5, SHA Encryption – 암호화, 복호화키를 통해 결과 값에서 원본 값으로 복원을 할 수 있는 양방향 알고리즘을 사용. 암호화에 사용. 대표 알고리즘 DES, AES, RSA
 Dual-Pivot Quick Sort ( Arrays.sort() 내부 정렬 알고리즘 )
Dual-Pivot Quick Sort ( Arrays.sort() 내부 정렬 알고리즘 )
Arrays.sort()는 내부적으로 3개의 Sorting을 쓴다. 1. Insertion Sort 2. Merge Sort 3. QuickSort 예전에는 3개를 분리하여서 각각의 경우에 따로 사용을 했지만 지금은 1,2 1,3을 섞어서 사용한다. Insertion Sort와 Merge Sort를 섞은 것은 Tim Sort Insertion Sort와 QuickSort를 섞은 것은 Dual-Pivot Quick Sort라고 한다. 여기서는 Insertion Sort를 합치지않은, 오로지 Dual-Pivot Quick Sort를 다룬다. 기존의 Quick Sort는 Pivot이 한개 였지만 Dual-Pivot Quick Sort는 Pivot을 2개를 써서 Pivot 1보다 낮은 그룹 / Pivot1 ~ ..
다음은 여러 가지 정렬 방법의 이론적 성능을 비교한 것이다. 최적 정렬 방법은 정렬해야 할 레코드의 수, 크기, 타입 등에 따라 달라지므로, 정렬 방법들의 장단점을 잘 이해하여 적합한 정렬 방법을 사용할 수 있어야 한다. 정수 60000개를 각 정렬 알고리즘으로 정렬할 때 소요되는 시간을 측정한 결과이다. 빨간 글씨로 색칠되어 있는 Insertion / Merge / Quick Sort는 Arrays.sort()에서 사용하는 정렬 알고리즘이므로 중요하다 생각되어 표시. 실제로는 Tim Sort(Insertion + Merge), Dual-Pivot Quick Sort(Quick Sort 변형) 2가지를 쓰지만 기본 베이스는 3가지이다. 알고리즘 Time Complexity 실행시간 (sec) Space ..
 기수 정렬 (Radix Sorting)
기수 정렬 (Radix Sorting)
앞의 정렬은 모두 레코드들을 비교하여 정렬하였다. 기수정렬은 레코드를 비교하지 않고 정렬하는 방법이다. 입력 데이터에 대해서 어떤 비교 연산도 하지 않고 데이터를 정렬할 수 있다. 정렬에 기초한 방법은 이라는 하한선을 깰 수 없는데 반해 기수 정렬은 이 하한을 깰 수 있는 유일한 정렬방법이다. 기수 정렬은 O(dn)의 시간 복잡도를 가지는데, 대부분 dfront = q->rear = 0; } // 공백 상태 검출 함수 int is_empty(QueueType *q) { return (q->front == q->rear); } // 포화 상태 검출 함수 int is_full(QueueType *q) { return ((q->rear + 1) % MAX_QUEUE_SIZE == q->front); } // ..
 히프 정렬 (Heap Sorting)
히프 정렬 (Heap Sorting)
히프는 우선순위 큐를 완전 이진 트리로 구현하는 방법으로 최댓값이나 최솟값을 쉽게 추출할 수 있는 자료구조이다. 최소 히프와 최대 히프가 있고 정렬에서는 최소 히프를 사용하는 것이 프로그램이 더 쉽다. 최소 히프는 부모 노드의 값이 자식 노드의 값보다 작기 때문에 최소 히프의 루트 노드는 가장 작은 값이다. 이러한 특성을 이용하여 정렬할 배열을 먼저 최소 히프로 변환한 다음, 가장 작은 원소부터 차례대로 추출하여 정렬하는 방법이다. 히프는 1차원 배열로 쉽게 구현될 수 있다. 최소 히프를 만들고 숫자들을 차례대로 삽입한 다음 최솟값(root)부터 삭제하면 된다. 최소 히프는 작은 값이 root고 이것부터 뽑아 내므로 오름차순 정렬, 최대 히프는 큰 값이 root이고 이것부터 뽑아 내므로 내림차순 정렬에 ..
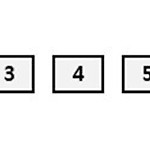 퀵 정렬 (Quick Sorting)
퀵 정렬 (Quick Sorting)
퀵 정렬은 평균적으로 매우 빠른 수행 속도를 보인다. 이 역시 분할 정복 방법에 근거한다. 합병 정렬과 비슷하게 전체 리스트를 2개의 부분 리스트로 분할한다. 각각의 부분 리스트를 다시 퀵 정렬하는 전형적인 분할 정복 방법을 사용한다. 그러나 퀵 정렬은 리스트를 다음과 같은 방법으로 비균등하게 분할한다. 먼저 리스트 안에 있는 한 요소를 피벗(pivot)으로 선택한다. 여기서는 리스트의 첫 번째 요소라고 가정한다. 피벗보다 작은 요소들은 모두 피벗의 왼쪽으로 옮겨지고, 피벗보다 큰 요소들은 모두 피벗의 오른쪽으로 옮겨진다. 결과적으로 피벗을 중심으로 왼쪽은 작은 요소들, 오른쪽은 큰 요소들로 구성된다. 이 상태에서 피벗을 제외한 왼쪽, 오른쪽 리스트를 다시 정렬하면 전체 리스트가 정렬된다. 퀵 정렬 역시..